










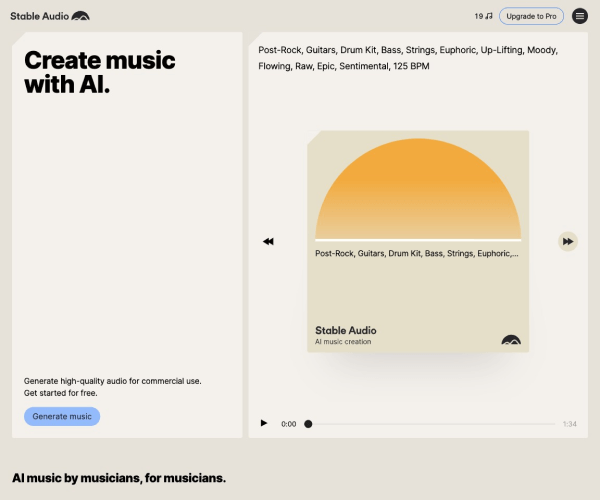
Stable Audio是由Stability AI开发的一款先进的音频生成模型。这个模型能够根据文本提示或上传的音频样本,生成高质量、长达三分钟的音乐作品,且支持多种音乐风格和结构。Stable Audio 2.0是该模型的升级版本,它不仅能够生成音乐,还具备音频到音频的生成能力,允许用户上传音频样本,并通过自然语言提示将其转换成各种声音。
Stable Audio 2.0的发布标志着人工智能在音频创作领域的应用迈出了新的里程碑。这个模型不仅仅局限于文本到音频的转换,而是能够处理和转换音频样本,为用户提供更广泛的声音创作可能性。Stable Audio 2.0特别训练了一个授权的数据集,该数据集来源于AudioSparx音乐图书馆,确保创作者的权益得到尊重和公平补偿。
用户可以在Stable Audio的网站上免费体验这个模型,并开始创作自己的音乐作品。这个平台提供了一个简单易用的网络界面,使得用户能够更快速、更高质量地生成音乐和音效。
注:以上内容均由智谱清言AI生成,仅供参考和借鉴!
©️版权声明:如涉及作品内容、版权和其它问题,请联系我方删除,我方将在收到通知后第一时间删除内容!本文只提供参考并不构成任何投资及应用建议。本站拥有对此声明的最终解释权。
类似网站









按住
Ctrl+D 或 ⌘+D
键,
把http://47.94.90.118/收藏起来吧!
术心导航官网收录了国内外数千个AI工具,全面涵盖了AI写作、AI图像处理、AI视频制作、AI对话聊天等多个领域。此外,还特别提供了视频剪辑、直播运营、后期制作等热搜职业岗位的运营资源,旨在帮助您轻松掌握这些技能,开启职业发展的新篇章。
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。

关注我们