










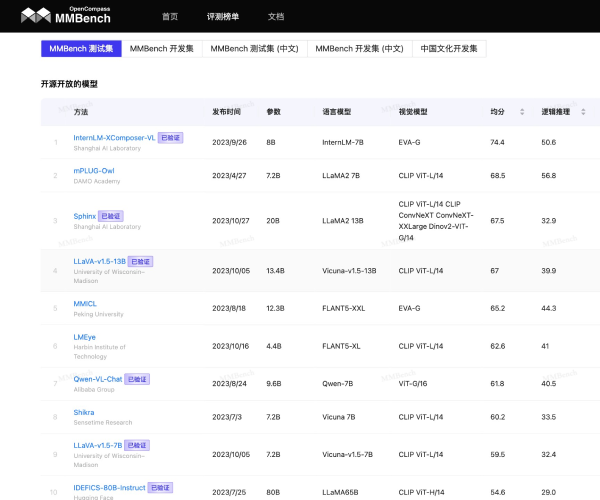
MMBench是一个用于评估指令微调视觉语言模型(VLM)各种能力的平台,具有以下特点:
评估维度:基于感知和推理,逐步细化评估维度,包括约3000个选择题,涵盖对象检测、文本识别、动作识别、图像字幕、关系推理等20多个细粒度评估维度。
评估方法:
更稳健的评估方法:通过重复相同的选择题并打乱选项,只有提供一致答案的模型才被认为通过,这种方法相比传统的1次通过率评估,平均准确率降低10%-20%,可减少噪声对评估结果的影响,确保可重复性。
更可靠的模型输出提取方法:基于ChatGPT匹配模型输出与选项,即使模型未按照指令输出,也能准确匹配到最合理的选项。
项目贡献者:由上海人工智能实验室、南洋理工大学、香港中文大学、新加坡国立大学、浙江大学等共同贡献。
引用信息:如果工作受到启发,可以使用特定的bib引用相关论文。
总之,MMBench为评估VLM的能力提供了一种全面、可靠的方法。
注:文案由豆包生成
©️版权声明:如涉及作品内容、版权和其它问题,请联系我方删除,我方将在收到通知后第一时间删除内容!本文只提供参考并不构成任何投资及应用建议。本站拥有对此声明的最终解释权。
类似网站







按住
Ctrl+D 或 ⌘+D
键,
把http://47.94.90.118/收藏起来吧!
术心导航官网收录了国内外数千个AI工具,全面涵盖了AI写作、AI图像处理、AI视频制作、AI对话聊天等多个领域。此外,还特别提供了视频剪辑、直播运营、后期制作等热搜职业岗位的运营资源,旨在帮助您轻松掌握这些技能,开启职业发展的新篇章。
Ctrl + D 或 ⌘ + D 收藏本站到浏览器书签栏。

关注我们